Interpretable and scalable quantum natural language processing
September 18, 2024
ŌĆŹThe central question that pre-occupies our team has been:
ŌĆ£How can quantum structures and quantum computers contribute to the effectiveness of AI?ŌĆØ
In previous work we have made notable advances in answering this question, and this article is based on our most recent work in the new papers [, ], and most notably the experiment in [].
This article is one of a series that we will be publishing alongside further advances ŌĆō advances that are accelerated by access to the most powerful quantum computers available.
Large language Models (LLMs) such as ChatGPT are having an impact on society across many walks of life. However, as users have become more familiar with this new technology, they have also become increasingly aware of deep-seated and systemic problems that come with AI systems built around LLMŌĆÖs.
The primary problem with LLMs is that nobody knows how they work - as inscrutable ŌĆ£black boxesŌĆØ they arenŌĆÖt ŌĆ£interpretableŌĆØ, meaning we canŌĆÖt reliably or efficiently control or predict their behavior. This is unacceptable in many situations. In addition, Modern LLMs are incredibly expensive to build and run, costing serious ŌĆō and potentially unsustainable ŌĆōamounts of power to train and use. This is why more and more organizations, governments, and regulators are insisting on solutions. ┬Ā
But how can we find these solutions, when we donŌĆÖt fully understand what we are dealing with now?1
At │į╣Ž║┌┴Ž═°, we have been working on natural language processing (NLP) using quantum computers for some time now. We are excited to have recently carried out experiments [] which demonstrate not only how it is possible to train a model for a quantum computer in a scalable manner, but also how to do this in a way that is interpretable for us. Moreover, we have promising theoretical indications of the usefulness of quantum computers for interpretable NLP [].
In order to better understand why this could be the case, one needs to understand the ways in which meanings compose together throughout a story or narrative. Our work towards capturing them in a new model of language, which we call DisCoCirc, is reported on extensively in this .
In new work referred to in this article, we embrace ŌĆ£compositional interpretabilityŌĆØ as proposed in [] as a solution to the problems that plague current AI. In brief, compositional interpretability boils down to being able to assign a human friendly meaning, such as natural language, to the components of a model, and then being able to understand how they fit together2.
A problem currently inherent to quantum machine learning is that of being able to train at scale. We avoid this by making use of ŌĆ£compositional generalizationŌĆØ. This means we train small, on classical computers, and then at test time evaluate much larger examples on a quantum computer. There now exist quantum computers which are impossible to simulate classically. To train models for such computers, it seems that compositional generalization currently provides the only credible path.
1. Text as circuits
DisCoCirc is a circuit-based model for natural language that turns arbitrary text into ŌĆ£text circuitsŌĆØ [, , ]. When we say that arbitrary text becomes ŌĆśtext-circuitsŌĆÖ we are converting the lines of text, which live in one dimension, into text-circuits which live in two-dimensions. These dimensions are the entities of the text versus the events in time.
To see how that works, consider the following story. In the beginning there is Alex and Beau. Alex meets Beau. Later, Chris shows up, and Beau marries Chris. Alex then kicks Beau.
The content of this story can be represented as the following circuit:
Figure 1. A text circuit for a simple story, involving three actors Alex, Beau andChris, who have a number of interactions with one another, making up a story ŌĆōthe circuit is to be read from top to bottom.
2. From text circuits to quantum circuits
Such a text circuit represents how the ŌĆśactorsŌĆÖ in it interact with each other, and how their states evolve by doing so. Initially, we know nothing about Alex and Beau. Once Alex meets Beau, we know something about Alex and BeauŌĆÖs interaction, then Beau marries Chris, and then Alex kicks Beau, so we know quite a bit more about all three, and in particular, how they relate to each other.
LetŌĆÖs now take those circuits to be quantum circuits.
In the last section we will elaborate more why this could be a very good choice. For now itŌĆÖs ok to understand that we simply follow the current paradigm of using vectors for meanings, in exactly the same way that this works in LLMs. Moreover, if we then also want to faithfully represent the compositional structure in language3, we can rely on theorem 5.49 from our book Picturing Quantum Processes, which informally can be stated as follows:
If the manner in which meanings of words (represented by vectors) compose obeys linguistic structure, then those vectors compose in exactly the same way as quantum systems compose.4
In short, a quantum implementation enables us to embrace compositional interpretability, as defined in our recent paper [].
3. Text circuits on our quantum computer
So, what have we done? And what does it mean?
We implemented a ŌĆ£question-answeringŌĆØ experiment on our │į╣Ž║┌┴Ž═° quantum computers, for text circuits as described above. We know from our new paper [] that this is very hard to do on a classical computer due to the fact that as the size of the texts get bigger they very quickly become unrealistic to even try to do this on a classical computer, however powerful it might be. This is worth emphasizing. The experiment we have completed would scale exponentially using classical computers ŌĆō to the point where the approach becomes intractable.
The experiment consisted of teaching (or training) the quantum computer to answer a question about a story, where both the story and question are presented as text-circuits. To test our model, we created longer stories in the same style as those used in training and questioned these. In our experiment, our stories were about people moving around, and we questioned the quantum computer about who was moving in the same direction at the end of the stories. A harder alternative one could imagine, would be having a murder mystery story and then asking the computer who was the murderer.
And remember - the training in our experiment constitutes the assigning of quantum states and gates to words that occur in the text.
Figure 2. The question-answering task for the language of text circuits as implementable on a quantum computer from []. Above the dotted line is the text we consider. Below are upside-down text circuits which constitute the question we ask. The boxes with words are parameterized as quantum gates. The diagram on the left constitutes one possible answer to the question, and the one on the right the other. Can you figure out what the text is and what the questions are?
4. Compositional generalization
The major reason for our excitement is that the training of our circuits enjoys compositional generalization. That is, we can do the training on small-scale ordinary computers, and do the testing, or asking the important questions, on quantum computers that can operate in ways not possible classically. Figure 4 shows how, despite only being trained on stories with up to 8 actors, the test accuracy remains high, even for much longer stories involving up to 30 actors.
Training large circuits directly in quantum machine learning, leads to difficulties which in many cases undo the potential advantage. Critically - compositional generalization allows us to bypass these issues.
Figure 3. A simplified plot from [] showing that increasing the sizes of circuits when testing doesnŌĆÖt affect the accuracy, after training small-scale on ordinary computers. The number of actors correlates with the text size. H1-1 is the name of the │į╣Ž║┌┴Ž═° quantum computer that was used.
5. Real-world comparison: ChatGPT
We can compare the results of our experiment on a quantum computer, to the success of a classical LLM ChatGPT (GPT-4) when asked the same questions.
What we are considering here is a story about a collection of characters that walk in a number of different directions, and sometimes follow each other. These are just some initial test examples, but it does show that this kind of reasoning is not particularly easy for LLMs.
The input to ChatGPT was:
What we got from ChatGPT:
Can you see where ChatGPT went wrong?
ChatGPTŌĆÖs score (in terms of accuracy) oscillated around 50% (equivalent to random guessing). Our text circuits consistently outperformed ChatGPT on these tasks. Future work in this area would involve looking at prompt engineering ŌĆō for example how the phrasing of the instructions can affect the output, and therefore the overall score.
Of course, we note that ChatGPT and other LLMŌĆÖs will issue new versions that may or may not be marginally better with ŌĆśquestion-answeringŌĆÖ tasks, and we also note that our own work may become far more effective as quantum computers rapidly become more powerful.
6. WhatŌĆÖs next?
We have now turned our attention to work that will show that using vectors to represent meaning and requiring compositional interpretability for natural language takes us mathematically natively into the quantum formalism. This does not mean that there doesn't exist an efficient classical method for solving specific tasks, and it may be hard to prove traditional hardness results whenever there is some machine learning involved. This could be something we might have to come to terms with, just as in classical machine learning.
At │į╣Ž║┌┴Ž═° we possess the most powerful quantum computers currently available. Our recently published roadmap is going to deliver more computationally powerful quantum computers in the short and medium term, as we extend our lead and push towards universal, fault tolerant quantum computers by the end of the decade. We expect to show even better (and larger scale) results when implementing our work on those machines. In short, we foresee a period of rapid innovation as powerful quantum computers that cannot be classically simulated become more readily available. This will likely be disruptive, as more and more use cases, including ones that we might not be currently thinking about, come into play.
Interestingly and intriguingly, we are also pioneering the use of powerful quantum computers in a hybrid system that has been described as a ŌĆśquantum supercomputerŌĆÖ where quantum computers, HPC and AI work together in an integrated fashion and look forward to using these systems to advance our work in language processing that can help solve the problem with LLMŌĆÖs that we highlighted at the start of this article.┬Ā
1 And where do we go next, when we donŌĆÖt even understand what we are dealing with now? On previous occasions in the history of science and technology, when efficient models without a clear interpretation have been developed, such as the Babylonian lunar theory or PtolemyŌĆÖs model of epicycles, these initially highly successful technologies vanished, making way for something else.
2 Note that our conception of compositionality is more general than the usual one adopted in linguistics, which is due to Frege. A discussion can be found in [].
3 For example, using pregroups here as linguistic structure, which are the cups and caps of PQP.
4 That is, using the tensor product of the corresponding vector spaces.
About │į╣Ž║┌┴Ž═°
│į╣Ž║┌┴Ž═°,┬Āthe worldŌĆÖs largest integrated quantum company, pioneers powerful quantum computers and advanced software solutions. │į╣Ž║┌┴Ž═°ŌĆÖs technology drives breakthroughs in materials discovery, cybersecurity, and next-gen quantum AI. With over 500 employees, including 370+ scientists and engineers, │į╣Ž║┌┴Ž═° leads the quantum computing revolution across continents.┬Ā
Blog
|
technical
June 10, 2026
│į╣Ž║┌┴Ž═°'s Fault-Tolerance Advantage: Turning Quantum Reliability into Commercial Usefulness
│į╣Ž║┌┴Ž═° continues its progress toward fault-tolerant quantum computing, with a series of peer-reviewed breakthroughs in fault-tolerant operations.ŌĆŹ
Our progress is not only scientific; it is commercial. By improving logical-qubit reliability and encoding efficiency, │į╣Ž║┌┴Ž═° is reducing the resource overhead required to scale its quantum computers toward commercially useful workloads.ŌĆŹ
These results were achieved on commercial │į╣Ž║┌┴Ž═° hardware, reinforcing that our architecture is not just setting new standards, but building a practical foundation for customers, partners, and researchers preparing for the fault-tolerant era.
Fault-tolerant quantum computing is the threshold the industry must cross before quantum computers can solve the hardest, highest-value problems with confidence. To be commercially useful at scale, the question is not simply who can build more qubits. It is who can build reliable, efficient, scalable systems that reduce technical risk and accelerate the path to commercial usefulness.
│į╣Ž║┌┴Ž═° is progressing on that path.
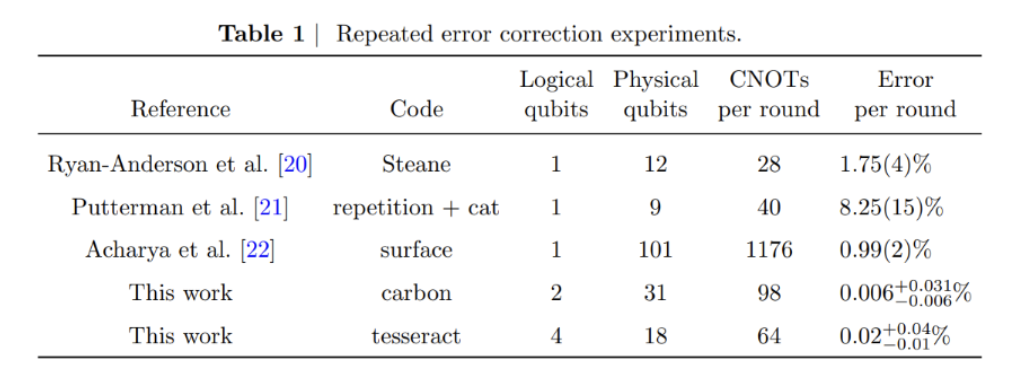
Last year, in partnership with Microsoft, we published a breakthrough in logical computing, demonstrating logical qubits that outperformed their physical counterparts by a factor of 800. We are proud to announce that this work is now being published in Nature, one of the most highly regarded scientific journals in the world. ┬Ā
This work highlights our leading fidelities, as shown in Table 1:
Since then, weŌĆÖve accelerated our efforts to reach large-scale fault tolerance and advanced what we believe to be the core building blocks of fault-tolerant quantum computing, from logical-qubit teleportation and multiple error-correction breakthroughs to one of the first meaningful computations using logical qubits. Importantly, these results were achieved on commercial │į╣Ž║┌┴Ž═° hardware, demonstrating not just scientific progress, but a practical and efficient path toward scalable, customer-ready fault tolerance.
Recently, we topped ourselves yet again by performing one of the first meaningful computations with logical qubits ŌĆō exploring key questions in materials and magnetism, using . This result also includes a leading ŌĆ£encoding rateŌĆØ squeezing 48 logical qubits out of just 98 physical qubits, emphasizing how our architecture helps to support large scale fault tolerance without enormous resource costs.
It is worth noting that all these results were achieved on our commercial hardware, not on one-off laboratory test-stands ŌĆō reflecting the performance that we are able to deliver to our customers.
We believe the commercial implication is clear: │į╣Ž║┌┴Ž═° is reducing the uncertainty around the path to fault-tolerant quantum computing. Our architecture, hardware fidelity, full-stack control, and error-correction progress are converging into a practical roadmap for systems that can support valuable scientific and commercial workloads.
For those evaluating when quantum computing will become strategically relevant, we believe the signal is also increasingly clear: the fault-tolerant era is no longer a distant concept. It is becoming an engineering reality, and │į╣Ž║┌┴Ž═° is leading the way.
Denmark Strengthens its Quantum Leadership with │į╣Ž║┌┴Ž═° Helios
University of Southern Denmark (SDU) to use │į╣Ž║┌┴Ž═° Helios, supported by the Danish e-Infrastructure Consortium (DeiC)
Access to Helios enables SDU to test and refine fault-tolerant algorithms and error-correction codes under realistic hardware conditions
The collaboration supports at a scale of 48 logical qubits, positioning Denmark at the forefront of scalable, practical quantum computing
Researchers exploring the scientific foundations for future development of applications in fields including pharmaceuticals, finance, and defense
Progress in quantum computing is measured by hardware advances plus the algorithms and quantum error-correction codes that turn quantum systems into useful computational tools.
Thanks to recent hardware advances, researchers are increasingly sharpening their tools to probe the performance of quantum algorithms and understand how they behave in realistic conditions ŌĆō where stability, system architecture and algorithm design all shape performance.
A new Denmark-based collaboration between the University of Southern Denmark (SDU), │į╣Ž║┌┴Ž═°, and the Danish e-Infrastructure Consortium (DeiC) will utilize │į╣Ž║┌┴Ž═° Helios. Researchers at the SDUŌĆÖs Centre for Quantum Mathematics, led by J├Ėrgen Ellegaard Andersen, will use Helios to pursue research into topological quantum computing.
Their work could help explain how and why successful quantum algorithms perform as they do, informing the development of high-performance algorithms suited to emerging quantum systems. TheyŌĆÖre exploring the scientific foundations that support future quantum applications across areas including pharmaceuticals, finance, and defense.
ŌĆ£We are thrilled to gain access to │į╣Ž║┌┴Ž═°ŌĆÖs high-fidelity Helios system. This collaboration gives us a unique opportunity to test the limits of our algorithms and evaluate system performance, while advancing fundamental research and laying the foundation for future applications.ŌĆØ ŌĆŹ ŌĆö Professor J├Ėrgen Ellegaard Andersen, Director of the Centre for Quantum Mathematics at University of Southern Denmark
Why topological methods matter
Topological quantum computing is an area of research that connects quantum computation with deep mathematical structures. It includes the study of error correcting codes known as surface codes that encode quantum information in the global properties of systems of logical qubits.
The research team will explore how these codes behave, and how they may support the development of fault-tolerant quantum algorithms in practical implementations under realistic conditions.
This distinction between theory and practical implementation matters. In theory, topological approaches offer a rich framework for designing algorithms and error-correcting codes. In practice, researchers need to understand how those ideas perform when implemented on real systems, where questions of noise, stability, overhead, and scaling become central. The collaboration will allow the SDU team to investigate these questions directly.
New ways to benchmark quantum processors
Beyond individual algorithms and codes, the research will also develop tools for benchmarking quantum processors. The goal is to develop new ways to characterize fidelity and stability in regimes that can be difficult to access.
The team will also explore hybrid quantumŌĆōclassical approaches, including machine-learning techniques assisted by quantum hardware, to study the mathematical structures at the heart of topological quantum computing. This work reflects a broader field of research in which quantum and classical methods are used together, each contributing to parts of a computational problem.
Strengthening DenmarkŌĆÖs quantum ecosystem
The collaboration reflects the growing role of national quantum infrastructure in supporting research and talent development. Denmark has a long tradition of scientific innovation, and this collaboration is intended to support the countryŌĆÖs continued development in quantum technology.
The initiative is supported by DeiC, which played a central role in securing funding and enabling access to │į╣Ž║┌┴Ž═°ŌĆÖs systems. DeiC has been assigned a particular role in developing and coordinating quantum infrastructure initiatives for the benefit of universities and industry, operating without its own commercial, sectoral, or geographical interests. This includes securing dedicated access to quantum computers, producing advisory services and supporting the development of new talent in the Danish quantum sector.
ŌĆ£DeiCŌĆÖs special effort to secure funding and access for this research initiative is rooted in our organizationŌĆÖs role in relation to the Danish GovernmentŌĆÖs strategy for quantum technology.ŌĆØ ŌĆŹ ŌĆö Henrik Navntoft S├Ėnderskov, Head of Quantum at Danish e-Infrastructure Consortium
This collaboration promises to accelerate the development of practical algorithms. It is grounded in fundamental science ŌĆō but its focus is practical: discovering and testing mathematical approaches to topological quantum computing that can be implemented, evaluated, and improved on real quantum hardware.
That work requires both theoretical insight and access to a system such as Helios capable of supporting meaningful scientific work.
This month, │į╣Ž║┌┴Ž═° welcomed its global user community to the first-ever Q-Net Connect, an annual forum designed to spark collaboration, share insights, and accelerate innovation across our full-stack quantum computing platforms. Over two days, users came together not only to learn from one another, but to build the relationships and momentum that we believe will help define the next chapter of quantum computing.
Q-Net Connect 2026 drew over 170 attendees from around the world to Denver, Colorado, including representatives from commercial enterprises and startups, academia and research institutions, and the public sector and non-profits - all users of │į╣Ž║┌┴Ž═° systems.┬Ā┬Ā
The program was packed with inspiring keynotes, technical tracks, and customer presentations. Attendees heard from leaders at │į╣Ž║┌┴Ž═°, as well as our partners at NVIDIA, JPMorganChase and BlueQubit; professors from the University of New Mexico, the University of Nottingham and Harvard University; national labs, including NIST, Oak Ridge National Laboratory, Sandia National Laboratories and Los Alamos National Laboratory; and other distinguished guests from across the global quantum ecosystem.
Congratulations to Q-Net Connect 2026 Award Recipients!┬Ā
The mission of the │į╣Ž║┌┴Ž═° Q-Net user community is to create a space for shared learning, collaboration and connection for those who adopt │į╣Ž║┌┴Ž═°ŌĆÖs hardware, software and middleware platform. At this yearŌĆÖs Q-Net Connect, we awarded four organizations who made notable efforts to champion this effort.┬Ā
JPMorganChase received the ŌĆśGuppy Adopter AwardŌĆÖ for their exemplary adoption of our quantum programming language, Guppy, in their research workflows.┬Ā
Phasecraft, a UK and US-based quantum algorithms startup, received the ŌĆśRising StarŌĆÖ award for demonstrating exceptional early impact and advancing science using │į╣Ž║┌┴Ž═° hardware, which they published in a December 2025 .
Qedma, a quantum software startup, received the ŌĆśStartup Partner EngagementŌĆÖ award for their sustained engagement with │į╣Ž║┌┴Ž═° platforms dating back to our first commercially deployed quantum computer, H1.
Anna Dalmasso from the University of Nottingham received our ŌĆśNew Student AwardŌĆÖ for her impressive debut project on │į╣Ž║┌┴Ž═° hardware and for delivering outstanding results as a new Q-Net student user.┬Ā
Congratulations, again, and thank you to everyone who contributed to the success of the first Q-Net Connect!
Become a Q-Net Member
Q-Net offers yearŌĆæround support through user access, developer tools, documentation, trainings, webinars, and events. Members enjoy many exclusive benefits, including being the first to hear about exclusive content, publications and promotional offers.
By joining the community, you will be invited to exclusive gatherings to hear about the latest breakthroughs and connect with industry experts driving quantum innovation. Members also get access to QŌĆæNet Connect recordings and stay connected for future community updates.